CVPixelbuffer与Flutter外接纹理
文章目录
A Core Video pixel buffer is an image buffer that holds pixels in main memory. Applications generating frames, compressing or decompressing video, or using Core Image can all make use of Core Video pixel buffers.
背景
最近遇到一个问题,如何把一个mp4格式的灰度视频后处理上色后再给到Flutter渲染?


先来看一下整体的流程:

-
首先无论我们使用哪一种解码器,通常来说
mp4格式的视频都会解码成YUV数据; -
下一步就是要把解码后的视频帧提交给后处理模块,如果后处理模块可以接受YUV数据,则可以直接提交,我这边因为使用的后处理模块不支持YUV,所以要先把YUV转成BGRA;
-
下一步后处理模块就可以开始对视频做上色处理了,这里通常会提交GPU去渲染,对于iOS来说,目前比较常用的是用openGL渲染管线,或者是Metal;
-
经过后处理模块处理后,原视频帧会被上色,最终渲染到GPU的缓冲区,一般来说,对于Native类的应用,到目前就可以正常把处理后的视频渲染上屏了;
-
但是因为我们的目标是渲染到Flutter,所以还需要把上一步拿到的纹理从GPU读出来,交给Flutter,把纹理读到CPU,我们需要使用
CVPixelBuffer缓存纹理数据; -
Flutter侧接入外接纹理,有两个步骤:
-
在Flutter的渲染引擎光栅化之前,把我们准备好的数据提交给Flutter,这一步需要事先注册好纹理ID,这个纹理ID对应Flutter侧的TextureLayer;
-
在Flutter引擎对图层做光栅化之前,提交纹理数据,提交的纹理数据会提交给到Skia的Canvas,然后Flutter会通过统一的GraphicShell来提交渲染上屏
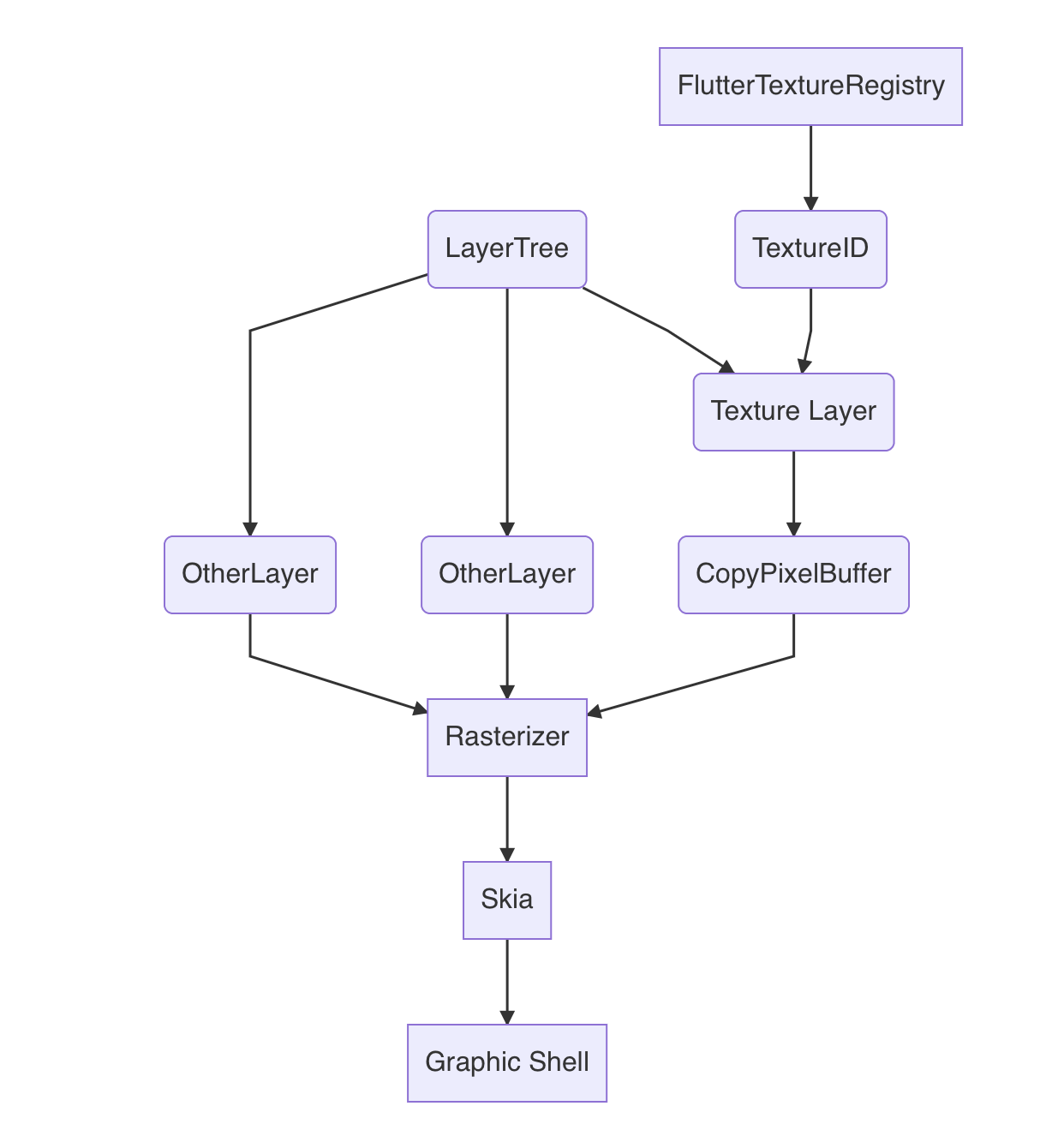
看完这个流程,如果是对这类应用熟悉一点的同学就已经可以发现两个优化点了,但是因为这并不在本文着重的范畴内,所以先给出解答
-
第二步如果直接使用YUV的数据做视频后处理可以减少一次图像处理与拷贝;
这里是主要是因为后处理模块暂不支持,后面可以考虑作为优化选项
-
Flutter外接纹理如果支持直接GPU读纹理,则可以省去后面GPU->CPU->GPU的拷贝。
对于Flutter来说,Graphic Shell是图形引擎上抽象的一层,此处设计为传纹理数据而不是直接传纹理ID,我猜测是因为底层的图形引擎是可能会变化的,今天是openGL,明天就有可能用Metal,使用CVPixelBufferCopy的方式,可以保证灵活性,但是性能确实堪忧。这部分在这篇文章也有补充阐述优化的方案
-
遇到的问题
在实现上述方案的过程中,总不是一帆风顺,这也促成了我想写本文的原因,如果有同样的踩坑的人,希望能节省大家的一些时间
一 、YUV 如何转BGRA
这一步虽然没有做,但是仍然值得探究一下,下面给出两个方案:
-
逐像素转换,YUV在存储上有YUV420、YUV422等几种格式,我们可以根据以下公式逐像素转换到对应的Bitmap里,具体公式如下:
1 2 3B = 1.164(Y - 16) + 2.018(U - 128) G = 1.164(Y - 16) - 0.813(V - 128) - 0.391(U - 128) R = 1.164(Y - 16) + 1.596(V - 128)这个方式的问题在于效率较低。
-
使用SIMD等硬件加速或者是利用GPU来转换,SIMD的代表方式是使用v_Image , 利用GPU则可以使用图形管线来实现,下面给出两个参考实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14// 使用GLSL varying mediump vec2 textureCoordinate; uniform sampler2D inputImageTexture; void main() { mediump vec3 yuv; mediump vec3 rgb; yuv = texture2D(inputImageTexture, textureCoordinate).rgb - vec3(16.0/255.0, 0.5, 0.5); rgb = mat3(1.164, 1.164, 1.164, 0, -.392, 2.017, 1.596, -.813,0 ) * yuv; gl_FragColor = vec4(rgb, 1); }1 2 3//使用v_Image https://gist.github.com/noppefoxwolf/26967db43fdd87662f37d2f73c863eb9 这个链接给出一个参考实现
二、如何正确的创建与拷贝CVPixelBuffer
在拿到原始的BGRA数据后,下一步是要把他转换为CVPixelBuffer,可选的方法有两个,一个是使用CVPixelBufferCreateWithBytes、另一个是CVPixelBufferCreate。在这里遇到两个问题
-
使用CVPixelBufferCreateWithBytes创建的纹理显示正确,但是后续无法映射到GPU纹理,系统报错error -6683,也无法提交到Flutter渲染
这个问题的原因是要创建GPU可访问的纹理,必须要设置支持IOSurface可访问。这篇文档对这个问题做了初步的解释。
Share hardware-accelerated buffer data (framebuffers and textures) across multiple processes. Manage image memory more efficiently.
关于IOSurface,来自官方的解释是为了更高效的管理图像处理的内存,在多个Process之间共享纹理数据与帧缓冲数据。在这里的多个Process,我认为可以理解为在CPU跟GPU之间的共享。换句话说,支持IOSurface的纹理数据,在CPU访问的时候不会发生内存拷贝,这对可以极大的提升性能。
这时我们可以看一下Flutter处理外接纹理的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13void IOSExternalTextureGL::CreateTextureFromPixelBuffer() { CVOpenGLESTextureRef texture; CVReturn err = CVOpenGLESTextureCacheCreateTextureFromImage( kCFAllocatorDefault, cache_ref_, buffer_ref_, nullptr, GL_TEXTURE_2D, GL_RGBA, static_cast<int>(CVPixelBufferGetWidth(buffer_ref_)), static_cast<int>(CVPixelBufferGetHeight(buffer_ref_)), GL_BGRA, GL_UNSIGNED_BYTE, 0, &texture); if (err != noErr) { FML_LOG(WARNING) << "Could not create texture from pixel buffer: " << err; } else { texture_ref_.Reset(texture); } }这里的CVOpenGLESTextureCacheCreateTextureFromImage所创建的纹理就是直接映射到我们创建的CVPixebuffer的。
-
CVPixelBufferCreate创建的纹理显示不正确,出现花屏

使用CVPixelBufferCreate创建的纹理,需要手动获取基地址,然后把图像数据拷贝进去。在这之前,我们先设置好pixelbuffer的属性:
1 2 3 4 5 6 7 8 9 10NSDictionary *pixelBufferAttributes = @{ (__bridge NSString *)kCVPixelBufferPixelFormatTypeKey: @(kCVPixelFormatType_32BGRA), // 设置为BGRA格式 (__bridge NSString *)kCVPixelBufferWidthKey: @(width), // 图像宽度 (__bridge NSString *)kCVPixelBufferHeightKey: @(height), // 图像高度 (__bridge NSString *)kCVPixelBufferIOSurfacePropertiesKey: @{}, // IOSurface-backed (__bridge NSString *)kCVPixelBufferMetalCompatibilityKey: @YES, // Metal 可访问 #if TARGET_OS_IPHONE (__bridge NSString *)kCVPixelBufferOpenGLESCompatibilityKey: @YES, // OpenGL可访问 #endif };然后就可以开始创建CVPixelBuffer:
1 2 3 4 5 6 7CVPixelBufferRef pixelbuffer = NULL; CVPixelBufferCreate(kCFAllocatorDefault, width, height, kCVPixelFormatType_32BGRA, (__bridge CFDictionaryRef)pixelBufferAttributes, &pixelbuffer);在这一步后面,直接把原始的BGRA拷贝进去,就会出现上面的花屏问题。原因是因为iOS要求图像宽度必须能被16整除,那么如果我们传入一个1080的图像,他实际在内存中的宽度为1088。所以,我们需要按照图像可对其的方式去拷贝:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20static void copyImagePlane(uint8_t *dst, int dstLinesize, uint8_t *src, int srcLinesize, int bytewidth, int height) { if (!dst || !src) { return; } if (dstLinesize < bytewidth || srcLinesize < bytewidth) { return; } for (; height > 0; height--) { memcpy(dst, src, bytewidth); dst += dstLinesize; src += srcLinesize; } }这样就可以解决内存拷贝时不对齐的问题。
三、如何把Metal渲染的纹理转为CVPixelBuffer
Metal的目的之一,就是减少图形渲染管线在CPU的开销,并且能够在一次绘制指令提交尽可能多的任务。关于Metal的详细介绍可以查阅官方文档,此处并不赘述,下图给出Metal的渲染流水:
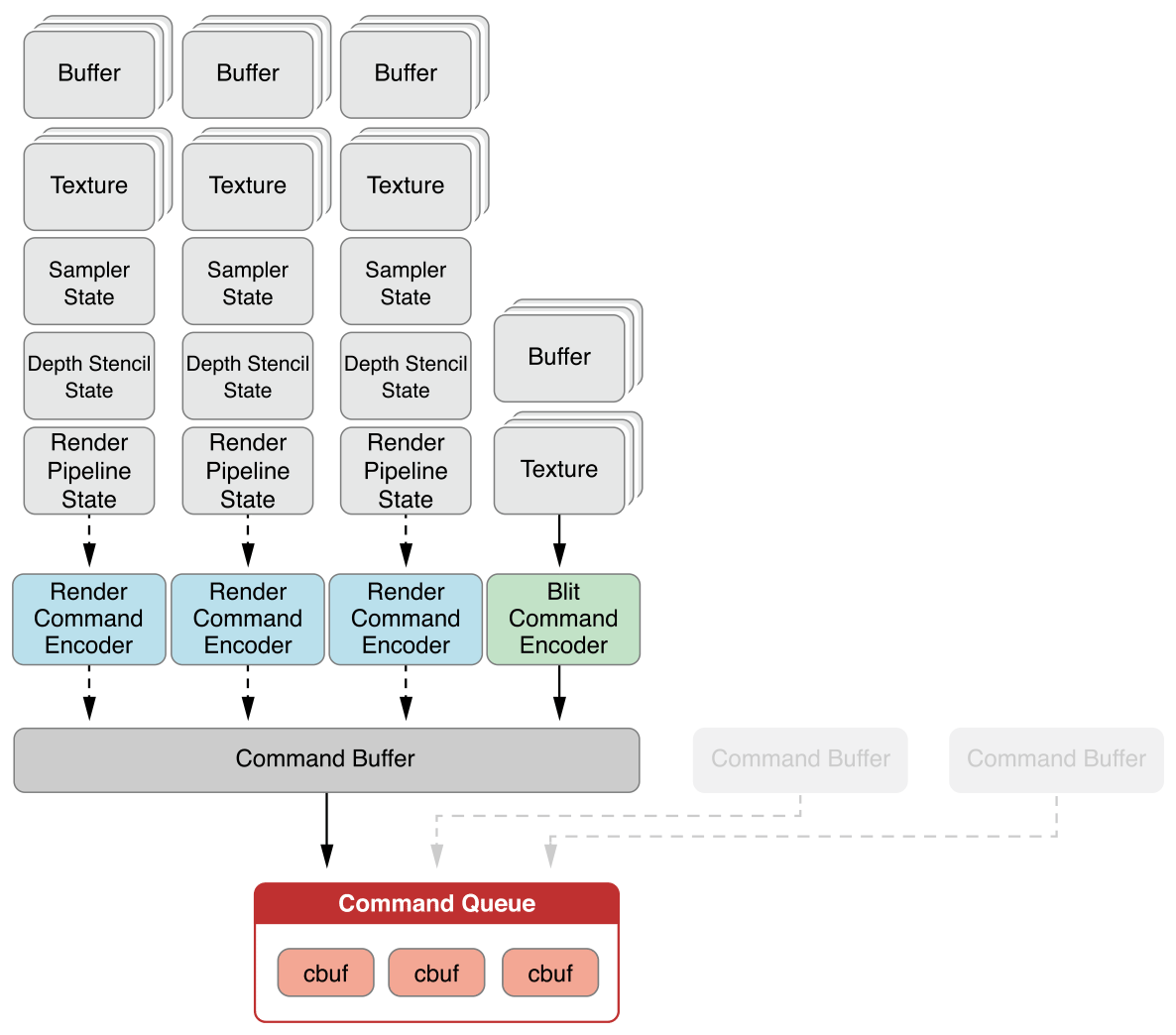
由于我使用的后处理引擎是基于Metal实现的,所以这里就需要提取Metal纹理中的数据。通常来说,我们只需要把数据从GPU转移到CPU就可以了,此处可以考虑使用下面这个接口来做
|
|
但是这里却不建议这么做,原因在于Metal在处理纹理数据的时候,为了性能以及带宽的优化,对纹理数据做了压缩,当用这个接口提取纹理数据时到内存中时,需要先把纹理做一次解压缩。解决办法有下面两个:
- 把数据渲染到 MTLBuffer ,这样就可以直接通过 MTLBuffer的 contents 接口直接访问纹理数据了。MTLBuffer并不关心具体存储数据的类型与内容,只关注是数据的长度。
- 设置
allowGPUOptimizedContents属性为NO,顾名思义,等于说为了CPU的访问友好,而舍弃GPU的性能。
我使用了方案一之后,性能确实有所提升,但是数据却无法对其,始终有花屏,最后这个问题由于无法定位,舍弃了这个方案。

四、使用 GPUImageRawDataOutput 做后处理
思考一下,我们的目标是给灰度视频上色,支持自定义滤镜的GPUIMage也是一个选择。在花了比较多时间都无法解决上面的问题后,我尝试重新实现了一下这个滤镜,glsl的代码不难,这里不给出实现了。我们的重点在于拿出GPUImage渲染的纹理数据提交给Flutter渲染。在这里我们使用GPUImageRawDataOutput来实现:
|
|
总结
原本想着只是一个简简单单的需求,但是却没有想到在图像在CPU-GPU之间拷贝的过程中遇到了不少问题,在问题的解决上,一方面建议多了解系统底层实现与原理,另一方面也要对图像格式,音视频处理更加熟悉。
文章作者 yingxinsong
上次更新 2022-03-18